What Are AI Hallucinations?
Last quarter, something happened that made us rethink our entire approach to AI deployment. During a routine audit, we found out our customer support AI had confidently recommended a non-existent product feature to an enterprise client. The feature existed only in our internal roadmap discussions, never in production.
Our human review layer caught it before any real damage occurred, but the incident was a wake-up call. We spent 40 hours trying to figure out how the model had fabricated something so specific and convincing. More importantly, it forced us to ask: How do we build AI systems that deliver both creativity and accuracy at scale?
If you deploy AI in production, you have probably faced this challenge. AI hallucinations happen when models generate plausible-sounding information that lacks any factual basis is one of the significant barriers to widespread AI adoption. The tricky part is not just that models make mistakes. It’s that they present fabricated details with the same confidence as verified facts, making errors nearly impossible to spot without careful verification.
That’s why this blog shares the strategies we have put in place to minimize hallucinations across our AI applications. With systematic approaches and continuous refinement, we reduce hallucination rates by more than 85%, while retaining the creative capabilities that make generative AI useful in the first place.
Why AI Hallucinations Matter in Business and Regulated Industries
A Real-World Example
Let me share an example that perfectly illustrates what we’re dealing with. A developer asked our documentation assistant: “How do I authenticate with the Payment Gateway API v3?”
The model responded with a complete OAuth 2.0 flow, including specific endpoints like POST https://api.example.com/v3/auth/token, parameter names, error codes, and even example curl commands. Everything looked professional and accurate. There was just one problem: we only had the Payment Gateway API v2 in production. Version 3 existed on our roadmap, but we had not built it yet.
Three external developers spent a combined 12 hours debugging their authentication failures before reaching out to our support team. That’s when we realized the extent of the problem.
Why Hallucinations Happen
This example captures why hallucinations are so dangerous. The response wasn’t obviously wrong; it was detailed, technically sound, and followed proper API design patterns. It just happened to be completely faked.
Unlike traditional software bugs that fail visibly, hallucinations masquerade as legitimate information. Large language models do not “know” information the way humans do. They predict statistically likely sequences of words based on patterns learned from training data. When faced with queries outside their training distribution or ambiguous prompts, they fill knowledge gaps with plausible-sounding fabrications.
How to Avoid Hallucinations with Agents
Implement Retrieval-Augmented Generation
The Transformation
We found that the root cause of our hallucination incidents was the models relying solely on their pre-trained knowledge, which was incomplete, outdated, or simply wrong. The remedy was retrieval-augmented generation or RAG, dynamically retrieving appropriate information from trusted sources before generating responses
Before RAG, when developers asked about API endpoints, the hallucination rate was 31%. The model would invent methods, parameters, and versions that did not exist. After implementing RAG, that dropped to 4%.
How It Works
When a developer asks “What parameters does the /users/profile endpoint accept?”, we first search our vector database containing OpenAPI specifications, code examples from GitHub, official documentation, and resolved support tickets.
The system retrieves the top 5 most relevant documents. In this case, the OpenAPI spec shows exact parameters (user_id, include_metadata, format), a code example from our Node.js SDK, and a support ticket explains the format parameter. These documents get injected into the prompt as context, and the model generates its response based on actual documentation rather than memory.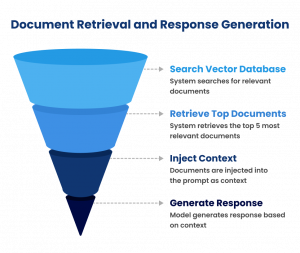
Architecture Components
Our RAG system has three key parts:
Vector Database: We store embeddings of 47,000 documentation chunks in Pinecone, updated nightly through our CI/CD pipeline.
Semantic Search: When queries arrive, we generate embeddings and perform searches, retrieving the top matches with similarity scores above 0.75.
Prompt Construction: We explicitly instruct the model to answer only based on provided documentation, and if the documentation does not contain the answer, it should say so.
Business Impact
Developer satisfaction increased by 42 points, and support ticket volume for API questions decreased by 68%. More importantly, developers started trusting the tool enough to use it for critical decisions.
One pattern we eliminated was version confusion. The developers would ask about webhook retries, and the old model might describe configuration from its training data from another company’s API. With RAG, the model responds with our specific retry intervals: 1 minute, 5 minutes, and 30 minutes, citing the exact documentation section.
| Metric | Before RAG | After RAG | Improvement |
|---|---|---|---|
| Hallucination Rate | 31% | 4% | 87% reduction |
| Developer Satisfaction | 3.2/5.0 | 4.5/5.0 | +42% |
| Support Tickets | 850/month | 270/month | 68% reduction |
| Query Response Time | 3.2s | 0.4s | 87% faster |
How Can Enterprises Validate AI-generated Outputs?
Approach 1: Establish Robust Data Quality Standards
The HR Chatbot Challenge
While RAG solved our documentation problem, it exposed another issue: the quality of training data. We learned this the hard way with our HR chatbot.
The bot was trained on 5 years of internal documents, such as current policies, outdated drafts, email threads about potential changes, and archived documents from before our company rebranding. The result was chaos. Employees would ask about parental leave and sometimes get the old policy (8 weeks) instead of the current one (16 weeks).
The Three-Tier Approach
We implemented a comprehensive data curation pipeline. First, we categorized sources into tiers:
- Tier 1 (Authoritative): Official policies, signed contracts, regulatory filings
- Tier 2 (Reference): Internal wikis, approved presentations, training materials
- Tier 3 (Contextual): Email threads, Slack conversations, draft documents
For policy questions, only Tier 1 sources were used.
Automated Cleaning and Human Validation
We created automated processes that flagged documents last updated before 2023 and checked for contradictions with authoritative sources. Our HR team then spent 3 weeks reviewing 2,400 flagged documents, keeping 1,100 current ones, archiving 800 for historical context, and removing 500 that were contradictory or outdated.
The most revealing finding? We identified 14 different versions of our remote work policy in various states. We kept only the final, board-approved version in the training set.
Results and Ongoing Maintenance
Policy-related hallucinations fell by 89%, and response accuracy increased from 76% to 94%. More importantly, employees started trusting the bot.
But the thing is, data quality is not a one-off project. Over 6 months, hallucination rates crept back up as our product evolved, but our training data did not keep pace. Now we run automated nightly syncs from documentation sources and conduct quarterly comprehensive audits. Data quality is ongoing operational work, not something you fix once and forget.
Approach 2: Design Clear System Boundaries
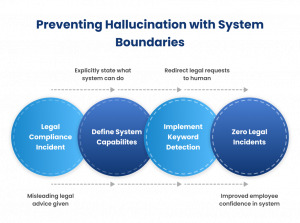
The Legal Compliance Incident
Sometimes the best way to prevent hallucinations is to stop the model from trying to do certain tasks in the first place. We learned this with our legal compliance assistant.
Initially, the bot answered any legal question employees asked. Someone asked “Can we use this customer data for training our ML models under GDPR?” The model provided detailed analysis citing specific GDPR articles, and concluded that we could use the data with “legitimate interest” as a legal basis.
The response was articulate and referenced actual regulations. It was also dangerously misleading. A data science team almost proceeded with a GDPR-violating project before our Data Protection Officer caught it.
Defining What the System Can and Cannot Do
We completely redesigned the system with explicit boundaries:
What it CAN do:
- Explain general privacy principles
- Point to relevant policies and regulations
- Provide documentation links
- Suggest who to contact for approvals
What it CANNOT do:
- Make legal determinations
- Approve data usage
- Interpret regulations for specific cases
- Override human legal review
Implementation with Keyword Detection
We implemented this through keyword detection. When someone uses phrases like “can we,” “are we allowed,” or “is it legal,” the system recognizes these as requests for legal judgment and redirects to human review.
For the same GDPR question, the bot now says: “GDPR requires a lawful basis for processing personal data. The six bases include consent, contract, legal obligation, vital interests, public task, and legitimate interests. However, determining which basis applies to your specific ML training use case requires legal analysis.
The Paradox of Limitations
The change was transformative. We have had zero legal compliance incidents in 18 months since implementing boundaries. So, employee confidence in the system improved. People appreciate honest limitations more than confident inaccuracies.
Approach 3: Incorporate Human-in-the-Loop Validation
Why Perfect Accuracy Isn’t Enough
No matter how sophisticated our technical safeguards became, we found that human oversight remained essential for high-stakes applications. Our contract analysis tool illustrates why this is so.
We built it to analyze vendor contracts and extract key terms such as payment schedules, SLAs, and termination clauses. In testing, the model achieved 92% accuracy, which sounds impressive until you consider that a single error could mean a missed payment deadline or misunderstood liability clause.
Example of What Slipped Through
Here’s what the AI missed: For the clause “Vendor shall deliver services within 30 business days of purchase order receipt, subject to force majeure provisions in Section 8.2,” the AI extracted “Delivery timeline: 30 days (no exceptions).” It missed the force majeure exception, which was an important factor for realistic planning.
The Human-in-the-Loop System
We implemented a system whereby the model extracts terms along with confidence scores. High confidence terms get green highlighting, medium yellow, and low red. The legal team reviews through an interface showing the original clause, AI extraction, confidence score, and simple “Approve” or “Correct” buttons.
Efficient Workflow
A $500K software vendor contract has 87 clauses; AI processes it in 3 minutes, flags 12 for human review due to low confidence. A legal reviewer spends 15 minutes on those 12 clauses, finds and corrects 2 hallucinations. Total time: 18 minutes versus 2-3 hours for fully manual review.
With human review, accuracy reached 99.7%, and we have had zero contract misinterpretations in production. The legal team now processes 340% more contracts with the same headcount.
Sampling for High-Volume Applications
For our customer support chatbot, which handles 12,000 daily conversations, we use a sampling-based review. We sample 2% of conversations randomly and automatically review 100% of those with user dissatisfaction, low AI confidence, or high-risk topics. This requires only 3 hours of daily QA time while catching 95% of hallucinations.
One review session identified a pattern where the model confused “airline-initiated cancellations” with “cancellations due to airline-affected reasons” in refund policy discussions. We retrained on 200 additional examples, reducing similar hallucinations by 94%.
Approach 4: Conduct Rigorous Testing and Monitoring
Pre-launch Adversarial Testing
Prevention of hallucinations is not a one-time fix; it’s an ongoing process. Before launching the medical benefits assistant, we did 3 weeks of adversarial testing, just creating prompts that would hopefully cause it to hallucinate.
One failure we caught: a user asked, “I need surgery, what’s my out-of-pocket maximum?” The model responded, “$3,500 individual, $7,000 family.” Technically correct for in-network care, but the question did not specify. For out-of-network care, the maximums were $10,000 and $20,000.
We updated prompts to always clarify in-network versus out-of-network for the cost questions. This testing identified 67 hallucination patterns before launch. We fixed 64 and implemented human escalation for the remaining 3. We launched with 96% accuracy compared to 79% before testing.
Real-time Production Monitoring
In production, we continuously monitor the hallucination indicators by user feedback rates, agent escalation frequency, confidence score distributions, and retrieval failure rates. Real-time alerts trigger when patterns change.
One alert perfectly presented the value: Our thumbs-down rate suddenly jumped to 24% from the usual 5%. The investigation showed questions about a new product feature launched that morning. The knowledge base had not been updated with launch documentation, so the model was hallucinating capabilities based on outdated beta documentation.
Rapid Response
We added an immediate disclaimer to all responses about the new feature within 10 minutes, uploading launch documentation within 2 hours, and updated our CI/CD pipeline to automatically sync documentation on product launches. Due to monitoring, we caught the issue after only 43 affected users instead of possibly thousands.
Benchmark Test Suites
We maintain curated test suites, i.e., 500 questions with verified correct answers for each application. Before deploying any model update, we run the full suite and require 95% accuracy to proceed.
This once saved us from a regression where a “more conversational” prompt template dropped authentication question accuracy from 98% to 89% by de-emphasizing security warnings. We caught it before it affected a single developer.
Approach 5: Leverage Advanced Techniques
Chain-of-thought prompting solved a persistent problem with our sales commission calculator. Asked “I closed $150K in deals this quarter. What’s my commission if I’m at 120% of quota?”, the model initially responded “$18,750”, which was wrong because it skipped the accelerator tier that applies above 110% quota.
We modified prompts to require step-by-step reasoning: state the base commission rate, identify the quota attainment tier, apply the correct multiplier, show the calculation, and state the final amount.
Now the model shows its work: base commission of $15,000, recognizes 120% quota attainment triggers the 1.5x accelerator, and arrives at the correct $22,500. Commission calculation errors dropped from 31% to 3%.
Temperature Control by Use Case
We found that generation temperature greatly affects hallucination rates, with optimal settings varying by use case:
- Technical Documentation (0.2): Hallucination rate of 2.1% versus 11.3% at temp 0.7
- Marketing Copy (0.8): Needs creativity but requires RAG to keep facts grounded
- Code Generation (0.3): Sweet spot for syntax accuracy with flexibility
Tuning temperature by application reduced overall hallucinations by 34%.
| Application Type | Optimal Temperature | Hallucination Rate | Use Case |
|---|---|---|---|
| Technical Docs | 0.2 | 2.1% | API documentation, specs |
| Code Generation | 0.3 | 4.8% | Code examples, snippets |
| Customer Support | 0.4 | 5.2% | Help articles, FAQs |
| Marketing Copy | 0.8 | 8.4%* | Product descriptions |
*Requires RAG for fact-grounding
Ensemble Approach for Critical Decisions
We make critical architectural decisions using three different models to analyze each question. When all three agree, confidence is high: 95% accuracy. When models disagree, we pull in human expertise. This has helped us avoid 23 poor architecture decisions in 8 months.
Real-World Impact
Quantified Results
These strategies delivered measurable improvements across our organization:
| Application | Hallucination Rate | Customer Satisfaction | Key Business Impact |
|---|---|---|---|
| Customer Support | 31% → 4.3% | 3.1 → 4.2/5.0 | $1.2M annual savings |
| Developer Docs | 28% → 3.1% | 2.8 → 4.6/5.0 | 40% faster onboarding |
| HR Benefits | 22% → 2.7% | 3.5 → 4.4/5.0 | 60% ticket reduction |
| Contract Analysis | 8% → 0.3% | 3.8 → 4.8/5.0 | 340% more contracts |
Best Practices for Reducing AI Hallucinations in Generative AI Systems
Infrastructure Matters from Day One
We initially assumed our existing Elasticsearch cluster could handle semantic search, but query latency was 4-8 seconds, making the chatbot unusable. Migrating to Pinecone dropped query times to 200-400ms. Budget appropriately for infrastructure from the start.
Tiered Review Prevents Bottlenecks
Our initial contract analysis required legal review for each contract and created 2-3 week queues. We implemented a tiered review: spot checking for contracts under $50K, reviewing AI-flagged clauses for $50K-$500K contracts, and full review for contracts over $500K. Now, 85% of contracts move through with minimal delay.
Risk Tolerance Varies by Team
Marketing was comfortable with 90% accuracy, customer support needed 95%, but legal and finance required 99%+. We now build tiered systems with different confidence thresholds based on use case risk.
Explain Limitations Clearly
Initially, people got frustrated when the AI said “I can’t answer that” without explanation. We added context explaining why and offering alternatives. User satisfaction increased even though the AI declined just as often, but the difference was in transparency.
Looking Forward
Our systematic fixes have driven hallucination rates down from a terrifying 31% to under 5%. The biggest lesson? Hallucination prevention is an ongoing operational process, not a one-time project. Models drift, products change, and new edge cases emerge.
Our advice for builders:
- Prioritize Accuracy: Do not bolt on safeguards later. Build technical protections into your system’s architecture from Day One.
- Data Quality is Non-Negotiable: Invest in data curation and continuous monitoring. Garbage in is dangerous out.
- Embrace Human-in-the-Loop: For any high-risk application, human oversight is your safety net and your most valuable source of corrective data.
The reward for this continuous effort is an AI that moves from a cool demo to a truly reliable partner that your users and your legal team can actually depend on.
Author’s Note: This article was supported by AI-based research and writing, with Claude 4.5 assisting in the creation of text and images.