Introduction
As AI-powered applications transition from experimental prototypes to mission-critical production services, resilience, scalability, and fault tolerance become paramount. Modern AI systems, particularly those leveraging large language models (LLMs) like Azure OpenAI, should handle network instability, quota limits, regional outages, and dynamic usage patterns.
This blog provides a practical guide to architecting resilient AI services using Python FastAPI microservices, Redis caching, Azure OpenAI Provisioned Throughput Units (PTUs), advanced retry logic, and robust disaster recovery strategies. We’ll also explore how secure configuration management via AWS Secrets Manager streamlines maintainability and boosts security.
Why Resilience is Non-Negotiable in AI
AI services, especially those relying on LLM APIs, face unique operational challenges:
- Rate and Quota Limits: API providers often impose token or request limits, requiring intelligent handling.
- Transient Failures: Network interruptions or server errors can intermittently cause requests to fail.
- Latency Sensitivity: Users expect near-real-time responses, making performance critical.
- Regional Failures: Cloud service outages can affect entire geographic regions.
Architecture Overview
One approach is to place an asynchronous microservice API built with FastAPI at the heart of the system. The microservices communicate with Azure OpenAI’s PTUs for LLM inference and rely on Redis (via AWS ElastiCache) for low-latency response caching. Sensitive credentials and retry configurations are stored in AWS Secrets Manager, and failover between Azure regions is orchestrated using Route 53 DNS geo-routing with health checks.
This layered design addresses both performance and fault tolerance. Redis reduces unnecessary API invocations; retry logic smooths over intermittent network glitches; and multi-region deployment ensures continuity during major outages.
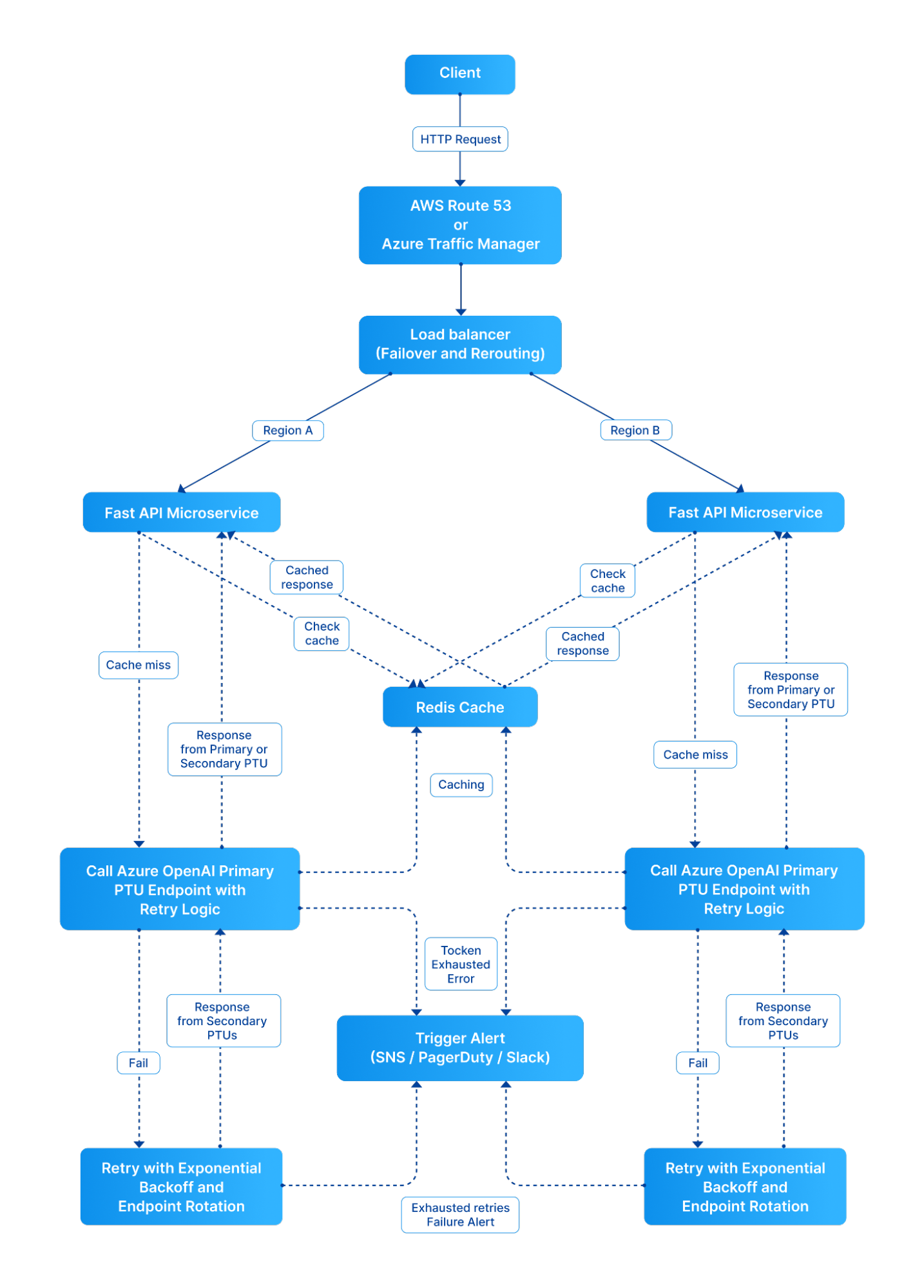 Architecture of an Enterprise-Grade AI
Architecture of an Enterprise-Grade AI
Our architecture leverages key components to ensure robustness:
| Component | Technology | Role |
|---|---|---|
| API Layer | Python FastAPI | Asynchronous, scalable microservice API |
| Caching Layer | Redis (AWS ElastiCache) | Low-latency response caching |
| AI Model Inference | Azure OpenAI PTUs | Managed, provisioned throughput for LLM inference |
| Configuration Storage | AWS Secrets Manager | Secure storage of API keys, secrets, and settings |
| Retry & Failover | Custom async retry with backoff | Resilient API calls with exponential backoff |
| Disaster Recovery | AWS Route 53 with Multi-region Azure | Automated failover and geo-routing |
Deep Dive into Key Resilience Enablers
Let’s explore how these components contribute to a robust AI service.
Supercharge APIs with FastAPI
FastAPI, an asynchronous Python web framework, delivers high concurrency and fast response times – ideal for AI backend microservices.
app = FastAPI()
@app.get(“/health”)
async def health_check():
return {“status”: “healthy”}
This endpoint, while simple, is pivotal to high-availability routing strategies such as those provided by AWS Route 53.
The Configuration Layer: Secure and Dynamic Settings
Embedding credentials or retry parameters in code introduces both security risk and operational rigidity. Instead, this architecture pulls secrets like API keys and retry policies from AWS Secrets Manager during application startup and caches them in memory using Python’s @lru_cache decorator.
import boto3
import json
from functools import lru_cache
@lru_cache()
def get_secrets(secret_name: str = “prod/llm-config”) -> dict:
client = boto3.client(“secretsmanager”)
response = client.get_secret_value(SecretId=secret_name)
return json.loads(response[“SecretString”])
This approach allows for dynamic updates to settings like retry policies or API keys without requiring a full service redeployment.
The Resilience Layer: Intelligent Retries and Failover
Failures in a distributed system are inevitable. The key is to handle them gracefully. Our resilience strategy is built on a few key concepts:
1. Redundancy with Multiple PTU Endpoints
A Provisioned Throughput Unit (PTU) from Azure OpenAI offers guaranteed processing capacity. However, a single PTU can become a bottleneck under high load or fail during a regional issue. To mitigate this, we provision multiple PTUs across different Azure regions (e.g., East US, West Europe). The application logic is designed to treat these PTU endpoints as a pool of resources. If a request to one endpoint fails, the system automatically retries with the next one in the pool. This provides both load balancing and regional redundancy.
2. Exponential Backoff with Jitter
When an API call fails from a transient error, retrying immediately can worsen the problem (a “retry storm”). To avoid this issue, a helpful approach is to implement exponential backoff with jitter. The delay between retries increases exponentially with each attempt (delay = base * (2 ** attempt)), and a small, random “jitter” is added to prevent clients from retrying in perfect sync. This gives the backend service time to recover.
3. Observability
You can’t fix what you can’t see. Using structured logging for every attempt allows the capturing of the endpoint used, the reason for failure, the delay applied, and the final outcome. These logs feed into monitoring dashboards (e.g., in Grafana) and trigger automated alerts when failure rates or token usage exceed predefined thresholds.
The Scalability Layer: Elastic Scaling with Kubernetes
To handle fluctuating demand, we deploy FastAPI services on Kubernetes and use the Horizontal Pod Autoscaler (HPA). The HPA automatically increases or decreases the number of service pods based on metrics like CPU utilization.
A sample HPA policy might look like this:
- Target CPU Utilization: 60%
- Minimum Replicas: 2
- Maximum Replicas: 20
This ensures that during a traffic spike or a regional failover event, our service can instantly scale up to meet the increased load, maintaining performance without manual intervention.
Key Takeaways
Building an enterprise-grade AI service means prioritizing resilience from day one. It isn’t an afterthought; it’s a core architectural requirement.
- Design for Failure: Assume that networks, APIs, and even entire cloud regions will fail. Build mechanisms to handle these events gracefully.
- Decouple and Centralize Configuration: Use a service like AWS Secrets Manager to manage settings externally. This improves security and operational agility.
- Implement Smart Retries: Use multiple redundant endpoints combined with exponential backoff and jitter to overcome transient issues without overwhelming your dependencies.
- Automate Scaling and Failover: Leverage tools like Kubernetes HPA and AWS Route 53 to create a system that can heal and adapt without human intervention.
By combining these practices, you can build AI services that are not only powerful but also deliver the stability and reliability that users expect.
Conclusion
AI systems operating at scale must be resilient by design. By combining asynchronous APIs, secure configuration, intelligent retries, cross-region failover, and auto-scaling, you can deliver AI services that remain stable, performant, and transparent even under adverse conditions.
The key insight: resilience isn’t an optimization—it’s a fundamental requirement for production AI systems.

Athiselvam N is a skilled CapeStart Senior Software Engineer who builds scalable, high-performance apps using Spring Boot, Angular, Node.js, MySQL, MongoDB, and Elasticsearch. He specializes in microservices, APIs, LLM, OpenAI, and Agentic AI, with expertise in Python, Redis, API Gateway, AWS, and Kubernetes. Passionate about innovation, he delivers impactful solutions across domains.